The power of Spatial Transformer Networks
tl;dr
A few weeks ago, Google DeepMind released an awesome paper called Spatial Transformer Networks aiming at boosting the geometric invariance of CNNs in a very elegant way.
This approach was so appealing to us at Moodstocks that we decided to implement it and see how it performs on a not-so-simple dataset called the GTSRB.
At the end of the day Spatial Transformer Networks enabled us to outperform the state-of-the-art with a much simpler pipeline (no jittering, no parallel networks, no fancy normalization techniques, …)
The GTSRB dataset
The GTSRB dataset (German Traffic Sign Recognition Benchmark) is provided by the Institut für Neuroinformatik group here. It was published for a competition held in 2011 (results). Images are spread across 43 different types of traffic signs and contain a total of 39,209 train examples and 12,630 test ones.

We like this dataset a lot at Moodstocks: it’s lightweight, yet hard enough to test new ideas. For the record, the contest winner achieved a 99,46% top-1 accuracy thanks to a committee of 25 networks and by using a bunch of augmentations and data normalization techniques.
Spatial Transformer networks
The goal of spatial transformers [1] is to add to your base network a layer able to perform an explicit geometric transformation on an input. The parameters of the transformation are learnt thanks to the standard backpropagation algorithm, meaning there is no need for extra data or supervision.
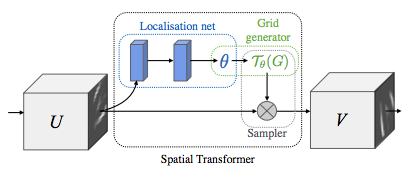
The layer is composed of 3 elements:
- The localization network takes the original image as an input and outputs the parameters of the transformation we want to apply.
- The grid generator generates a grid of coordinates in the input image corresponding to each pixel from the output image.
- The sampler generates the output image using the grid given by the grid generator.
As an example, here is what you get after training a network whose first layer is a ST:

On the left you see the input image. In the middle you see which part of the input image is sampled. On the right you see the Spatial Transformer output image.
Results
The IDSIA guys won the contest back in 2011 with a 99.46% top-1 accuracy. We achieved a 99.61% top-1 accuracy with a much simpler pipeline:
- (i) 5 versions of the original dataset thanks to fancy normalization techniques
- (ii) scaling translations and rotations
- (iii) 25 networks with 3 convolutional layers and 2 fully connected layers each
- (iv) A single network with 3 convolutional layers and 2 fully connected layers + 2 spatial transformer layers
Interpretation
Given these good results, we wanted to have some insights on which kind of transformations the Spatial Transformer is learning. Since we have a Spatial Transformer at the beginning of the network we can easily visualize its impact by looking at the transformed input image.
At training time
Here the goal is to visualize how the Spatial Transformer behaves during training.
In the animation below, you can see:
- on the left the original image used as input,
- on the right the transformed image produced by the Spatial Transformer,
- on the bottom a counter that represents training steps (0 = before training, 10/10 = end of epoch 1).

Note: the white dots on the input image show the corners of the part of the image that is sampled. Same applies below.
As expected, we see that during the training, the Spatial Transformer learns to focus on the traffic sign, learning gradually to remove background.
Post-training
Here the goal is to visualize the ability of the Spatial Transformer (once trained) to produce a stable output even though the input contains geometric noise.
For the record the GTSRB dataset has been initially generated by extracting images from video sequences took while approaching a traffic sign.
The animation below shows for each image of such a sequence (on the left) the corresponding output of the Spatial Transformer (on the right).

We can see that even though there is an important variability in the input images (scale and position in the image), the output of the Spatial Transformer remains almost static.
This confirms the intuition we had on how the Spatial Transformer simplifies the task for the rest of the network: learning to only forward the interesting part of the input and removing geometric noise.
The Spatial Transformer learned these transformations in an end-to-end fashion, without any modification to the backpropagation algorithm and without any extra annotations.
Code
We leveraged the grid generator and the sampler coded by Maxime Oquab in his great stnbhwd project. We added a module placed between the localization network and the grid generator to let us restrict the possible transformations.
Using these modules, creating a spatial transformer layer using torch logic is as easy as:
The full code is available on the Moodstocks Github. We designed it to let you perform a large range of tests on the dataset. If you are looking at reproducing our results, all you need is run the following command:
# This takes ~5 min per epoch and 1750MB ram on a Titan X
luajit main.lua -n -1 --st --locnet 200,300,200 --locnet3 150,150,150 --net idsia_net.lua --cnn 150,200,300,350 -e 14
It will basically add two Spatial Transfomer layers (--st --locnet 200,300,200 --locnet3 150,150,150) to the baseline IDSIA network (idsia_net.lua --cnn 150,200,300,350) and run for 14 epochs (-e 14). Of course you can do much more with our code, so feel free to check out the docs in our repo!
Conclusion
Spatial Transformer Networks are a very appealing way to boost the geometric invariance of CNNs and hence improve your top-1 accuracy. They learn to account for geometric transformations relevant to your dataset without the need for extra supervision. Using them we managed to outperform the state-of-the-art on a not-so-simple dataset (GTSRB) while drastically simplifying the pipeline. Feel free to use our code to reproduce our results or even get better ones: we provide a fancy way to mass benchmark configurations to help you do that. Have fun!
- Max Jaderberg, Karen Simonyan, Andrew Zisserman, Koray Kavukcuoglu, Spatial Transformer Networks [arxiv]
- P. Sermanet, Y. LeCun, Traffic sign recognition with multi-scale Convolutional Networks [link]
- D. Ciresan, U. Meier, J. Masci, J. Schmidhuber, Multi-column deep neural network for traffic sign classification [link]