The Torch Blog

-
Jul 25, 2016
Language modeling a billion words
Noise contrastive estimation is used to train a multi-GPU recurrent neural network language model on the Google billion words dataset.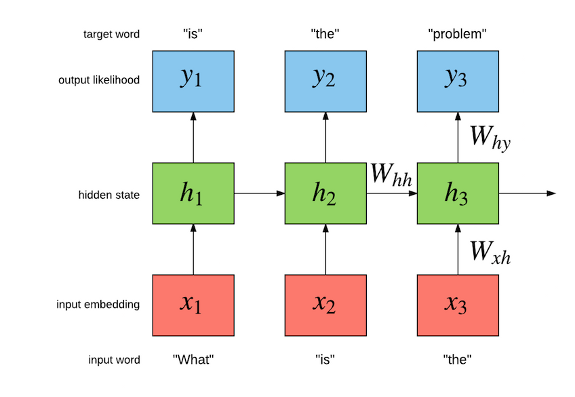 </img>
</img>
-
Jun 1, 2016
Deep Fun with OpenCV and Torch
In this post, we'll have some fun with OpenCV 3.0 + Torch to build live demos of Age & Gender Classification, NeuralStyle, NeuralTalk and live Image classification. </img>
</img>
-
Apr 30, 2016
Dueling Deep Q-Networks
Deep Q-networks have been a great step forward in the field of reinforcement learning, achieving superhuman performance on the domain of Atari 2600 video games. In this post we explain how they work, and discuss some of the developments since Google DeepMind's publication in Nature - particularly the dueling DQN. </img>
</img>
-
Feb 4, 2016
Training and investigating Residual Nets
In this blog post we implement Deep Residual Networks (ResNets) and investigate ResNets from a model-selection and optimization perspective. We also discuss multi-GPU optimizations and engineering best-practices in training ResNets. We finally compare ResNets to GoogleNet and VGG networks.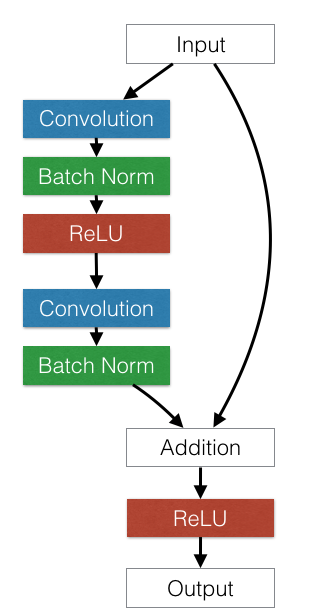 </img>
</img>
-
Nov 13, 2015
Generating Faces with Torch
In this blog post we implement a Generative Adversarial network (GAN) and train it to output images of human faces. GANs are notoriously hard to train, and we explore a handful of tricks to stabilize/speed up convergence. Moreover, we combine GANs with a variational autoencoder to arrive at an encoder/decoder architecture capable of producing interesting images! </img>
</img>
-
Sep 21, 2015
Recurrent Model of Visual Attention
Visual Attention models have recently had success in object detection and image captioning. It is especially interesting to see the models have a human-like attention. In this post, we discuss our implementation of the recurrent attention model, which involves some Reinforcement learning, along with insights and code. </img>
</img>
-
Sep 7, 2015
The power of Spatial Transformer Networks
Spatial Transformers are an exciting new learnable layer that can be plugged into ConvNets. We show that using these layers in a ConvNet gets us to state of the art accuracy with a significantly smaller network. We also explore and visualize the learning that happens in the transform layers. </img>
</img>
-
Jul 30, 2015
92.45% on CIFAR-10 in Torch
CIFAR-10 is a popular vision dataset for trying out new ideas. We show that using a simple combination of Batch Normalization and a VGG-like convnet architecture, one can get a competitive baseline on the dataset. </img>
</img>
</body> </html>