Language modeling a billion words
- Word versus character language models
- Recurrent neural network language models
- Loading the Google billion words dataset
- Building a multi-layer LSTM
- Training and evaluation scripts
- Results
- Future work
- References
In our last post, we presented a recurrent model for visual attention which combined reinforcement learning with recurrent neural networks. In this Torch blog post, we use noise contrastive estimation (NCE) [2] to train a multi-GPU recurrent neural network language model (RNNLM) on the Google billion words (GBW) dataset [7]. The work presented here is the result of many months of on-and-off work at Element-Research. The enormity of the dataset caused us to contribute some novel open-source Torch modules, criteria and even a multi-GPU tensor. We also provide scripts so that you can train and evaluate your own language models.
If you are only interested in generated samples, perplexity and learning curves, please jump to the results section.
Word versus character language models
In recent months you may have noticed increased interest in generative character-level RNNLMs like char-rnn and the more recent torch-rnn. These models are very interesting as they can be used to generate sequences of characters like the following:
<post>
Diablo
<comment score=1>
I liked this game so much!! Hope telling that numbers' benefits and
features never found out at that level is a total breeze
because it's not even a developer/voice opening and rusher runs
the game against so many people having noticeable purchases of selling
the developers built or trying to run the patch to Jagex.
</comment>
The above was generated one character at a time using a sample of reddit comments.
As you can see for yourself, the general structure of the generated text looks good, at first view.
The tags are opened and closed appropriately. The first sentence looks good: I liked this game so much!!
and it is related to the subreddit of the post: Diablo. But reading the rest of it, we can
start to see the limitations of char-level language models. The spelling of individual words looks great, but
the meaning of the next sentence is difficult to understand (it is also very long).
In this blog post we will show how Torch can be used to train a large-scale word-level language model to generate independent sentences. Word-level models have an important advantage over char-level models. Take the following sequence as an example (a quote from Robert A. Heinlein):
Progress isn't made by early risers. It's made by lazy men trying to find easier ways to do something.
After tokenization, the word-level model might view this sequence as containing 22 tokens. On the other hand, the char-level will view this sequence as containing 102 tokens. This longer sequence makes the task of the character model harder than the word model, as it must take into account dependencies between more tokens over more time-steps. Another issue with character language models is that they need to learn spelling in addition to syntax, semantics, etc. In any case, word language models will typically have lower error than character models.[8]
The main advantage of character over word language models is that they have a really small vocabulary. For example, the GBW dataset will contain approximately 800 characters compared to 800,000 words (after pruning low-frequency tokens). In practice this means that character models will require less memory and have faster inference than their word counterparts. Another advantage is that they do not require tokenization as a preprocessing step.
Recurrent neural network language models
Our task is to build a language model which maximizes the likelihood of the next word given the history of previous words in the sentence. The following figure illustrates the workings of a simple recurrent neural network (Simple RNN) language model:
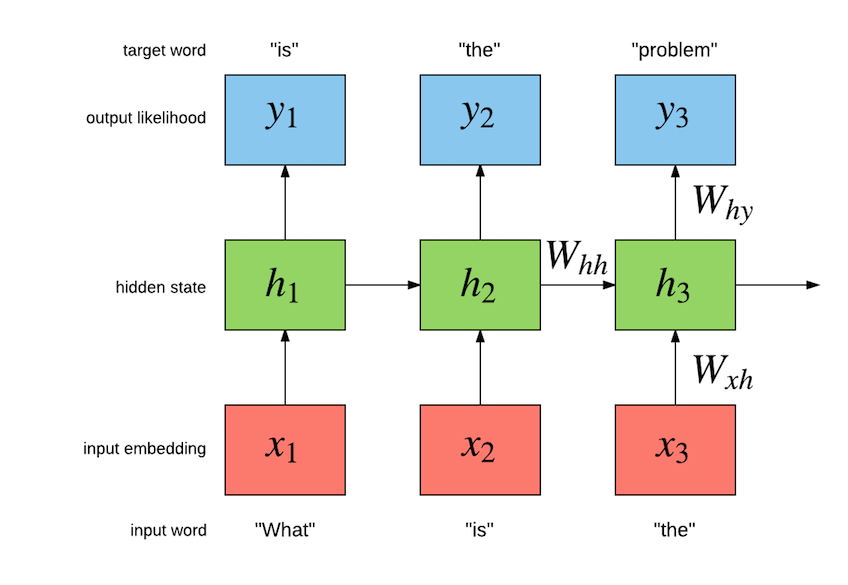
The exact implementation is as follows:
h[t] = σ(W[x->h]x[t] + W[h->h]h[t−1] + b[1->h]) (1)
y[t] = softmax(W[x->y]h[t] + b[1->y]) (2)
For this particular example, the model should maximize “is” given “what”, and then “the” given “is” and so on.
The Simple RNN has an internal hidden state h[t] which summarizes the sequence fed in so far, as it relates to maximizing the likelihood of the remaining words in the sequence.
Internally, the Simple RNN has parameters from input to hidden (word embeddings), hidden to hidden (recurrent connections) and hidden to output (output embeddings that feed into a softmax).
The input to hidden parameters consist of a LookupTable that learns to represent each word as a vector.
These vectors form a embeddings space for words.
The input x[t] to the LookupTable is a unique integer associated to the word w[t].
The embedding vector for that word is obtained by indexing the embedding space W[x->h] which we represent by W[x->h]x[t].
The hidden to hidden parameters model the temporal dependencies of words by generating a hidden state h[t] given h[t-1] and x[t].
This is where the actual recurrence takes place as h[t] is a function of h[t-1] (and word x[t]).
The hidden to output layer does an affine transform (i.e. a Linear module: W[x->y]h[t] + b[1->h]) followed by a softmax.
This is to estimate a probability distribution y[t]over the next word given the previous words which is emboddied by the hidden state h[t].
The criterion is to maximize the likelihood of the next word w[t+1] given previous words:
P(w[t+1]|w[1],w[2],...,w[t]).
Simple RNNs are easy to build using the rnn package (see simple RNN example), but they are not the only kind of model that can be used model language. There are also the more advanced Long Short Term Memory (LSTM) models [3],[4],[5], which have special gated cells that facilitate the backpropagation of gradients through longer sequences.
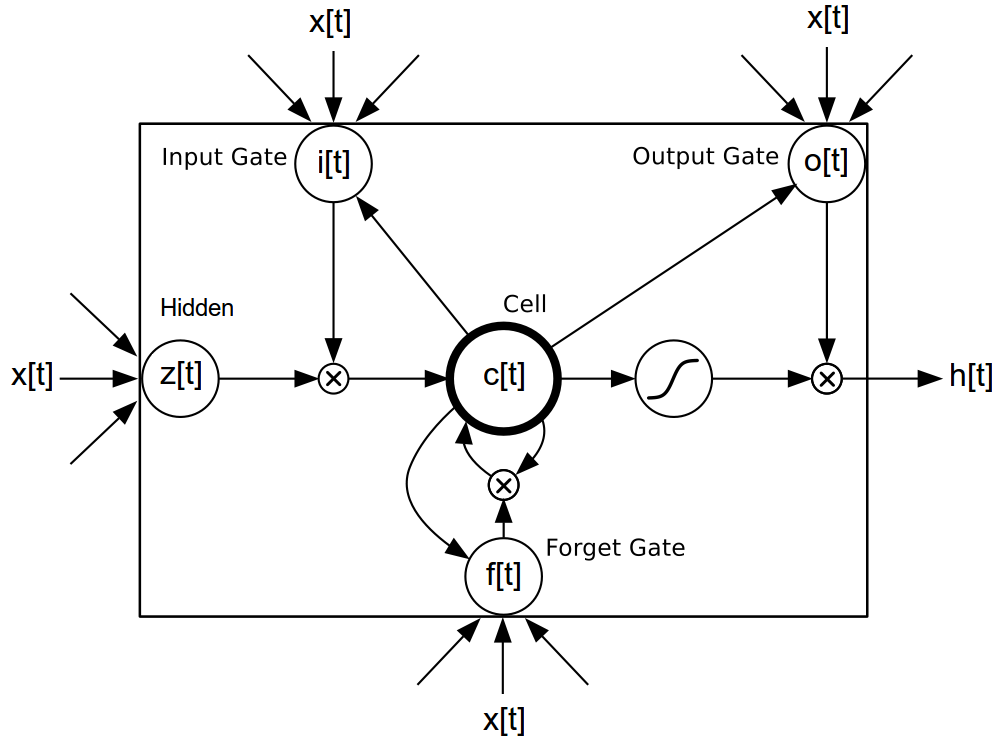
The exact implementation is as follows:
i[t] = σ(W[x->i]x[t] + W[h->i]h[t−1] + b[1->i]) (3)
f[t] = σ(W[x->f]x[t] + W[h->f]h[t−1] + b[1->f]) (4)
z[t] = tanh(W[x->c]x[t] + W[h->c]h[t−1] + b[1->c]) (5)
c[t] = f[t]c[t−1] + i[t]z[t] (6)
o[t] = σ(W[x->o]x[t] + W[h->o]h[t−1] + b[1->o]) (7)
h[t] = o[t]tanh(c[t]) (8)
The main advantage is that LSTMs can learn dependencies between words seperated between much longer time-steps.
It isn’t as prone to the problems of vanishing gradients as the different gates can preserve the gradients during back-propagation.
To create a LM, the word embeddings (W[x->h]x[t] in eq.1) would be fed to the LSTM and the resulting hidden state would be fed to eq. 2.
The error of language model is traditionally measured using perplexity.
Perplexity is a measure of how surprised the model is to see a sequence of text.
If you feed it in a sequence of words, and for each successive word the model is able to
predict with high likelihood what word comes next, it will have low perplexity.
If the next word in the sequence s of length T is indexed by s[t] and the model-inferred likelihood is y[t] such that
the likelihood of that word is y[t][s[t]], then the perplexity of that sequence of words is:
log(y[1][s[1]) + log(y[2][s[2]) + ... + log(y[T][s[T])
PPL(s,y) = exp( -------------------------------------------------------- )
-T
The lower the perplexity, the better.
Loading the Google billion words dataset
For our word-level language model we use the GBW dataset. The dataset is different from Penn Tree Bank in that sentences are kept independent of each other. So then our dataset consists of a set of independent variable-length sequences. The dataset can be easily loaded using the dataload package:
local dl = require 'dataload'
local train, valid, test = dl.loadGBW(batchsize)
The above will automatically download the data if not found on disk and return the training, validation and test set. These are dl.MultiSequence instances which have the following constructor:
dataloader = dl.MultiSequence(sequences, batchsize)
The sequences argument is a Lua table or tds.Vector
where each element is a Tensor containing an independent sequence. For example:
sequences = {
torch.LongTensor{424,158,115,667,28,505,228},
torch.LongTensor{389,456,188},
torch.LongTensor{77,172,760,687,552,529}
}
batchsize = 2
dataloader = dl.MultiSequence(sequences, batchsize)
Note how the sequences vary in length.
Like all dl.DataLoader sub-classes, the
dl.MultiSequence loader provides a method for sub-sampling a batch of inputs and targets from the dataset:
local inputs, targets = dataloader:sub(1, 10)
The sub method takes the start and end indices of sub-sequences to index.
Internally, these indices are only used to determine length (seqlen) of the requested multi-sequences.
Each successive call to sub will return multi-sequences contiguous to the previous ones.
The returned inputs and targets are seqlen x batchsize [x inputsize]
tensors containg a batch of 2 multi-sequences, each containing 8 time-steps.
Starting with the inputs :
print(inputs)
0 0
424 77
158 172
115 760
667 687
28 552
505 0
0 424
[torch.DoubleTensor of size 8x2]
Each column is a vector containing potentially multiple sequences, i.e. a multi-sequence.
Independent sequences are seperated by zeros. In the next section, we will see how the
rnn package can use these zero-masked time-steps to
efficiently forget its hidden state between independent sequences (at the granularity of columns).
For now, notice how the original sequences are contained in the returned inputs and separated by zeros.
The targets are similar to the inputs, but use masks of 1 to separate sequences (as ClassNLLCriterion will otherwise complain).
As is typical in language models, the task is to predict the next word, such that the targets are delayed by one time-step
with respect to the commensurate inputs:
print(targets)
1 1
158 172
115 760
667 687
28 552
505 529
228 1
1 158
[torch.DoubleTensor of size 8x2]
The train, valid and test returned by the call to dl.loadGBW have the same properties as the above.
Except that the dataset is much bigger (it has one billion words). For debugging and such, we can choose to
load a smaller subset of the training set. This will load much faster than the default training set file:
local train, valid, test = dl.loadGBW({2,2,2}, 'train_tiny.th7')
The above will use a batchsize of 2 for all sets.
Iteration through the dataloader is made easier using the subiter :
local seqlen, epochsize = 3, 10
for i, inputs, targets in train:subiter(seqlen, epochsize) do
print("T = " .. i)
print(inputs)
end
Which will output:
T = 3
0 0
793470 793470
211427 6697
[torch.DoubleTensor of size 3x2]
T = 6
477149 400396
720601 213235
660496 368322
[torch.DoubleTensor of size 3x2]
T = 9
676607 61007
161927 767587
248714 635004
[torch.DoubleTensor of size 3x2]
T = 10
280570 130510
[torch.DoubleTensor of size 1x2]
We could also return the above batches as one big chunk instead:
train:reset() -- resets the internal sequence iterator
print(train:sub(1,10))
0 0
793470 793470
211427 6697
477149 400396
720601 213235
660496 368322
676607 61007
161927 767587
248714 635004
280570 130510
[torch.DoubleTensor of size 10x2]
Notice how the above small batches are aligned with this big chunk. Which means that the data is iterated in sequence.
Each sentence in the GBW dataset is encapsulated by <S> and </S> tokens to indicate the
start and end of the sequence, respectively. Each token is mapped to an integer. So for example,
you can see that <S> is mapped to integer 793470 in the above example.
Now that we feel confident in our dataset, lets look at the model.
Building a multi-layer LSTM
In this section, we get down to the business of actually building our multi-layer LSTM. We will introduce NCE once we get to the output layer, starting from the input layer.
The input layer of the the lm model is a lookup table :
lm = nn.Sequential()
-- input layer (i.e. word embedding space)
local lookup = nn.LookupTableMaskZero(#trainset.ivocab, opt.inputsize)
lm:add(lookup) -- input is seqlen x batchsize
A sub-class of LookupTable, we use the LookupTableMaskZero
to learn word embeddings. The main difference is that it supports zero-indexes, which are forwarded as zero-tensors.
Then we have the actual multi-layer LSTM implementation, which uses the SeqLSTM module:
local inputsize = opt.inputsize
for i,hiddensize in ipairs(opt.hiddensize) do
local rnn = nn.SeqLSTM(inputsize, hiddensize)
rnn.maskzero = true
lm:add(rnn)
if opt.dropout > 0 then
lm:add(nn.Dropout(opt.dropout))
end
inputsize = hiddensize
end
As demonstrated in the rnn-benchmarks repository, the SeqLSTM implemention is very fast.
Next we split the output of the SeqLSTM (which is a seqlen x batchsize x outputsize Tensor) into a table containing a batchsize x outputsize tensor for
each time-step:
lm:add(nn.SplitTable(1))
The problem: bottleneck at the output layer
With its small vocabulary of 10000 words, the Penn Tree Bank dataset is relatively easy to use to build word-level language models.
The output layer is still computationally tractable for both training and inference, especially for GPUs.
For these smaller vocabularies, the output layer is basically a Linear followed by a SoftMax:
outputlayer = nn.Sequential()
:add(nn.Linear(hiddensize, vocabsize))
:add(nn.SoftMax())
However, when training with large vocabularies, like the 793471 words that makes up the GBW dataset ,
the output layer quickly becomes a bottleneck.
For example, if you are training your model with a batchsize = 128 (number of sequences per batch) and a seqlen = 50
(size of sequence to backpropagate through time),
the output of that layer will have shape seqlen x batchsize x vocabsize, or 128 x 50 x 793471.
For a FloatTensor or CudaTensor, that single tensor will take up 20GB of memory!
The number can be double for gradInput (i.e. gradients with respect to input),
and double again as both Linear and SoftMax store a copy for the output.
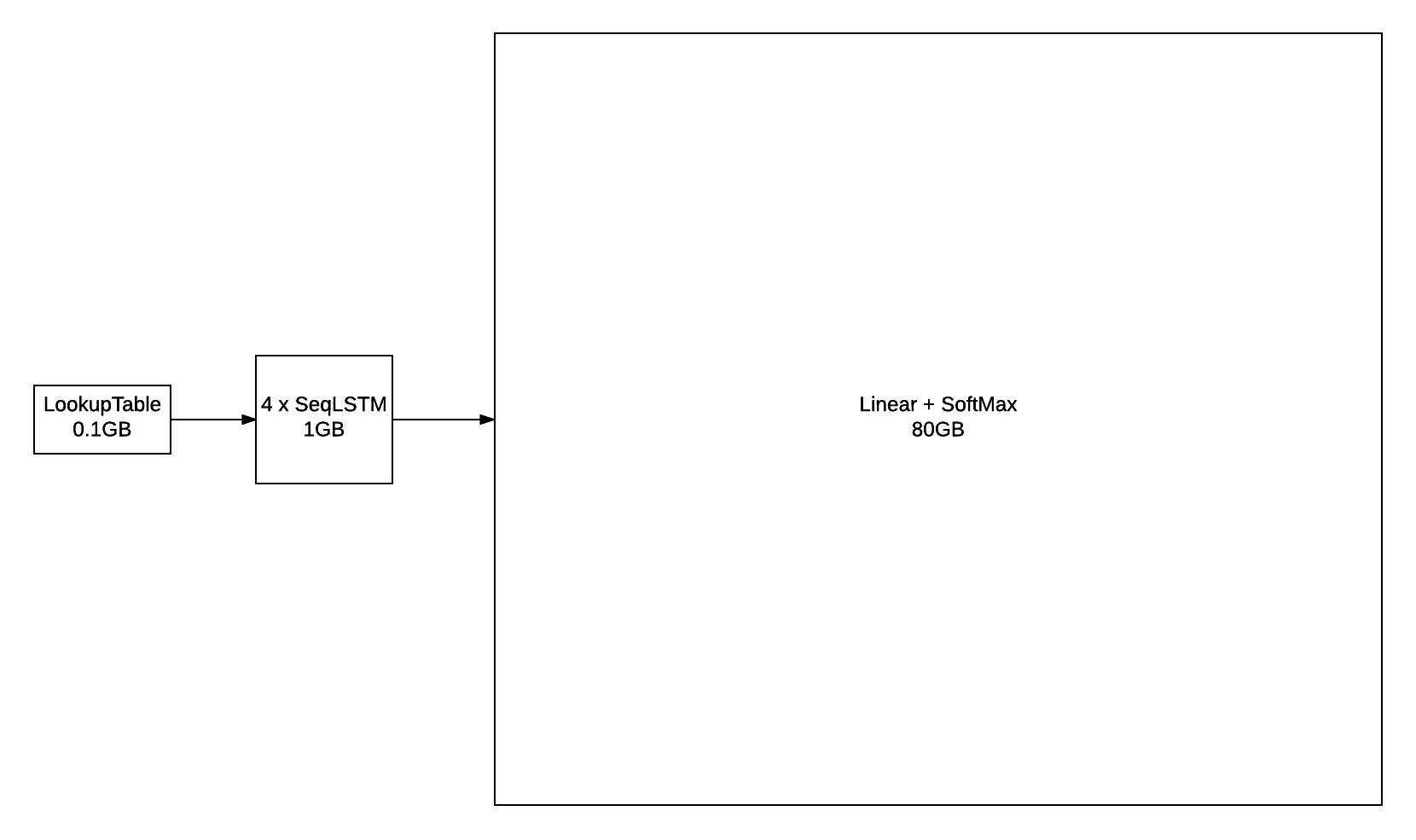
Excluding parameters and their gradients, the above figure outlines the approximate memory consumption of a 4-layer LSTM with 2048 units with a seqlen=50.
Even if somehow you can find a way to put 80GB on a GPU (or distribute it over many), you still run into the problem of
forward/backward propagating through that outputlayer in a reasonable time-frame.
The solution: noise contrastive estimation
The output layer of the LM uses NCE to speed up training and reduce memory consumption:
local unigram = trainset.wordfreq:float()
local ncemodule = nn.NCEModule(inputsize, #trainset.ivocab, opt.k, unigram, opt.Z)
-- NCE requires {input, target} as inputs
lm = nn.Sequential()
:add(nn.ParallelTable()
:add(lm):add(nn.Identity()))
:add(nn.ZipTable())
-- encapsulate stepmodule into a Sequencer
lm:add(nn.Sequencer(nn.MaskZero(ncemodule, 1)))
The NCEModule is a more efficient version of:
nn.Sequential():add(nn.Linear(inputsize, #trainset.ivocab)):add(nn.LogSoftMax())
For evaluating perplexity, the model still implements Linear + SoftMax.
NCE is useful for reducing the memory consumption during training (compare to the figure above):
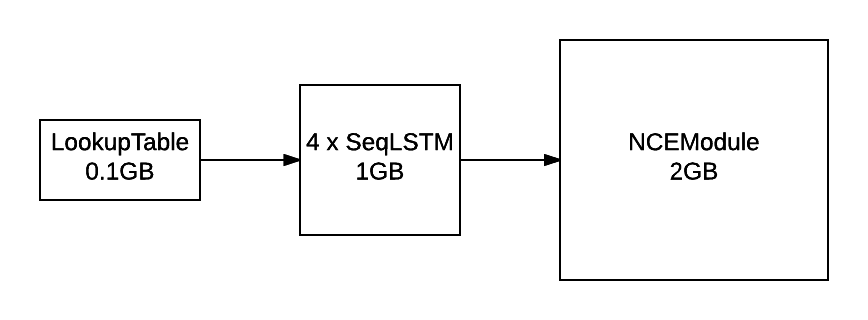
Along with the NCECriterion,
the NCEModule implements the algorithm is described in [1].
I won’t go into the details of the algorithm as it involves a lot of math which is more appropriately detailed in the reference papers.
The way it works is that for each target word (the likelihood of which we want to maximize),
k words are sampled from a noise distribution, which is typically the unigram distribution.
Remember that a softmax is basically:
exp(x[i])
y[i] = --------------------------------- (9)
exp(x[1])+exp(x[2])+...+exp(x[n])
where x[i] is the i-th output of the output Linear layer.
The above denominator is the cause of the bottleneck as the Linear needs to be computed for each output x[i].
For a n=797470 vocabulary, this is prohibitively expensive.
NCE goes around this problem by replacing the denominator of eq. 9 with a constant Z during training:
exp(x[i])
y[i] = ------------ (10)
Z
Now this is not what actually happens during training as back-propagating through the above will not produce gradients
for the x[j] where j~=i (j not equal i).
Notice that backpropagating through eq. 9 will produce gradients for all outputs x of the Linear (i.e. for all i).
Another problem with eq. 10 is that nothing is pushing exp(x[1])+exp(x[2])+...+exp(x[n]) to approximate Z.
What NCE does is formulate the problem such that k noise samples can be included in the equation to
both make sure that some (at most k) negative samples (i.e. x[j] where j) get gradients and that the denominator of eq. 9 approximates the denominator of eq. 10.
The k noise samples are sampled from a noise distribution, i.e. the unigram distribution.
The output layer Linear need only be computed for the target and noise-sampled words, which is where the efficiency is gained.
The unigram variable above is a tensor of size 793470 where each element is the frequency of the commensurate word in the corpus.
Sampling from such a large distribution using something like torch.multinomial
can become a bottleneck during training.
So we implemented a more efficient version in torch.AliasMultinomial.
The latter multinomial sampler requires more setup time than the former, but this isn’t a problem as the unigram distribution is constant.
NCE uses the noise samples to approximate a normalization term Z where the output distribution is exp(x[i])/Z and x[i] is the output of the Linear for word i.
For the Softmax, which NCE tries to approximate, the Z is the sum over the exp(x[i']) over all words i'.
For NCE, the Z is typically fixed to Z=1.
Our initial experiments found that setting Z to Z=N*mean(exp(x[i]))
(where N is the number of words and the mean is approximated over a small batch of word samples i)
gave much better results, but this is because we weren’t appropriately initializing the output layer parameters.
One notable aspect of NCE papers (there are many) is that they often forget to mention the importance of this parameter initialization.
Setting Z=1 is only really possible if the NCEModule.bias is initialized to bias[i] = -log(N).
This is what the authors of [2] use, although it isn’t mentioned in the paper (I contacted one of the authors to find out).
Sampling k noise samples per time-step and per batch-row means that the NCEModule needs to internally use something like
torch.baddbmm to compute the output.
Reference [2] implement a faster version where the noise samples are drawn once and used for the entire batch (but still once for each time-step).
This makes the code a bit faster as the more efficient torch.addmm can be used instead of torch.baddbmm.
This faster NCE version described in [2] is the default implementation of the NCEModule. Sampling per batch-row can be turned on with NCEModule.rownoise=true.
Training and evaluation scripts
The experiments presented here use three scripts: two for training (you only need to use one) and one for evaluation. The training scripts only differ in the amount of GPUs to use. Both train a language model on the training set and do early-stopping on the validation set. The evaluation script is used to measure the perplexity of a trained model on the test set, or to generate sentences.
Single-GPU training script
We provide training scripts for a single gpu via the noise-contrastive-estimate.lua script. Running the following on a 12GB NVIDIA Titan X should resulted in a test set perplexity of 65.6 after 321 epochs:
th examples/noise-contrastive-estimate.lua --cuda --device 2 --startlr 1 --saturate 300 --cutoff 10 --progress --uniform 0.1 --seqlen 50 --batchsize 128 --trainsize 400000 --validsize 40000 --hiddensize '{250,250}' --k 400 --minlr 0.001 --momentum 0.9
The resulting model will look like this:
nn.Serial @ nn.Sequential {
[input -> (1) -> (2) -> (3) -> output]
(1): nn.ParallelTable {
input
|`-> (1): nn.Sequential {
| [input -> (1) -> (2) -> (3) -> (4) -> output]
| (1): nn.LookupTableMaskZero
| (2): nn.SeqLSTM
| (3): nn.SeqLSTM
| (4): nn.SplitTable
| }
|`-> (2): nn.Identity
... -> output
}
(2): nn.ZipTable
(3): nn.Sequencer @ nn.Recursor @ nn.MaskZero @ nn.NCEModule(250 -> 793471)
}
To use about one third less memory, you can set momentum of 0.
Evaluation script
The evaluation script can be used to measure perplexity on the test set or sample independent sentences. To evaluate a saved model, you can use the evaluate-rnnlm.lua script:
th scripts/evaluate-rnnlm.lua --xplogpath /home/nicholas14/save/rnnlm/gbw:uranus:1466538423:1.t7 --cuda
where you should replace /home/nicholas14/save/rnnlm/gbw:uranus:1466538423:1.t7 with the path to your own trained model.
Evaluating on the test set can take a while as it must use the less efficient Linear + SoftMax, and thus a very small batch size (so as not to use too much memory).
The evaluation script can also be used to generate samples from the language model:
th scripts/evaluate-rnnlm.lua --xplogpath /home/nicholas14/save/rnnlm/gbw:uranus:1466790001:1.t7 --cuda --nsample 200 --temperature 0.7
The --nsample flag specifies how many tokens to sample. The first token input to the language model is the start-of-sentence tag (<S>).
When the end-of-sentence tag (</S>), the model’s hidden states are set to zero, such that each sentence is sampled independently.
The --temperature flag can be reduced to make the sampling more deterministic.
<S> There were a number of players in the starting lineup during the season and in recent weeks , in recent years , some fans have been frustrated . </S>
<S> WASHINGTON ( Reuters ) - The government plans to cut greenhouse gases by as much as 12 % on the global economy , a new report said . </S>
<S> One of the most important things about the day was that the two companies had just been guilty of the same nature . </S>
<S> " It has been as much a bit of a public service as a public organisation . </S>
<S> In a nutshell , it 's not only the fate of the economy . </S>
<S> It was last modified at 23.31 GMT on Saturday 22 December 2009 . </S>
<S> He told the newspaper the prosecution had been treating the small boy as " a young man who was playing for a while . </S>
<S> " We are astounded that our employees are not made aware of the risks and risks they are pursuing during this period of time , " he said . </S>
<S> " I had a right to come up with the idea . </S>
Multi-GPU training script
As can be observed in the previous section, training a 2-layer LSTM with only 250 hidden units will not yield the best generated samples. The model needs much more capacity than what can fit on a 12GB GPU. For parameters and their gradients, a 4x2048 LSTM model requires the following:
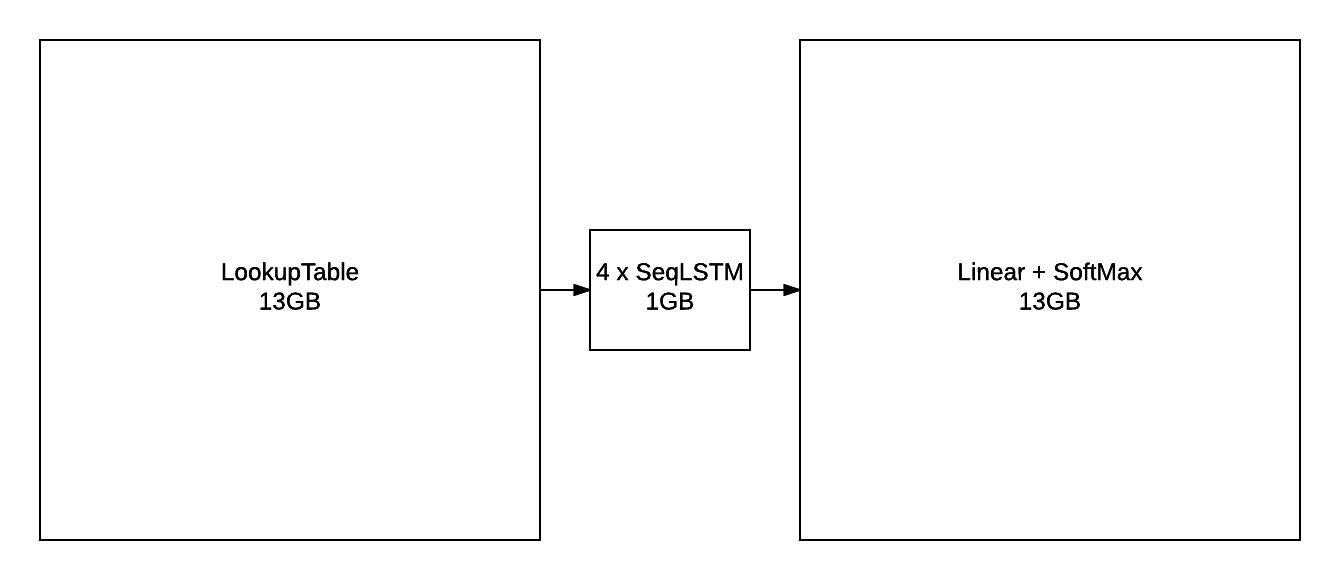
This doesn’t include all the intermediate buffers required for the different modules (outlined in NCE section). The solution was of course to distribution the model over more GPUs. The multigpu-nce-rnnlm.lua script is thus provided to train a language model on four GPUs.
It uses the GPU (which we contributed it to the nn) to decorate modules such that
all their operations and memory are hosted on a specified device.
The GPU module won’t parallelize kernel execution over different GPU-devices.
But it does allow us to distribute large models over devices.
For our LM, the input word embeddings (i.e. LookupTableMaskZero) and output layer (i.e. NCEModule) take up most of the memory.
The first was pretty easy to distribute:
lm = nn.Sequential()
lm:add(nn.Convert())
-- input layer (i.e. word embedding space)
local concat = nn.Concat(3)
for device=1,2 do
local inputsize = device == 1 and torch.floor(opt.inputsize/2) or torch.ceil(opt.inputsize/2)
local lookup = nn.LookupTableMaskZero(#trainset.ivocab, inputsize)
lookup.maxnormout = -1 -- prevent weird maxnormout behaviour
concat:add(nn.GPU(lookup, device):cuda()) -- input is seqlen x batchsize
end
Basically, the embedding space is split into two tables.
For a 2048 unit embedding space, half, i.e. 1024 units, are located on each of two devices.
We use Concat to concatenate them back together after a forward.
For the hidden layers (i.e. SeqLSTM), we just distribute them on the devices used by the input layer.
The hidden layers use up little memory (approximately 1GB each) so they aren’t the problem.
We locate them on the same devices as the input layer as the output layer utilizes more memory (for buffers).
local inputsize = opt.inputsize
for i,hiddensize in ipairs(opt.hiddensize) do
local rnn = nn.SeqLSTM(inputsize, hiddensize)
rnn.maskzero = true
local device = i <= #opt.hiddensize/2 and 1 or 2
lm:add(nn.GPU(rnn, device):cuda())
if opt.dropout > 0 then
lm:add(nn.GPU(nn.Dropout(opt.dropout), device):cuda())
end
inputsize = hiddensize
end
lm:add(nn.GPU(nn.SplitTable(1), 3):cuda())
The NCEModule was a bit more difficult to distribute as it cannot be so easily parallelized as LookupTableMaskZero.
Our solution was to provide a simple multicuda()
method to distribute the weight on gradWeight on different devices.
This is accomplished by swaping the weight tensors for our own : torch.MultiCudaTensor.
Lua has no severe type-checking system, so you can fake a tensor by creating a torch.class table with the same methods.
To save time, the current version of MultiCudaTensor only supports the operations required by the NCEModule.
The advantage of this approach is that it requires minimal changes to the NCEModule and maintains backward compatiblity without requiring redundant code or excessive refactoring.
-- output layer
local unigram = trainset.wordfreq:float()
ncemodule = nn.NCEModule(inputsize, #trainset.ivocab, opt.k, unigram, opt.Z)
ncemodule:reset() -- initializes bias to get approx. Z = 1
ncemodule.batchnoise = not opt.rownoise
-- distribute weight, gradWeight and momentum on devices 3 and 4
ncemodule:multicuda(3,4)
-- NCE requires {input, target} as inputs
lm = nn.Sequential()
:add(nn.ParallelTable()
:add(lm):add(nn.Identity()))
:add(nn.ZipTable())
-- encapsulate stepmodule into a Sequencer
local masked = nn.MaskZero(ncemodule, 1):cuda()
lm:add(nn.GPU(nn.Sequencer(masked), 3, opt.device):cuda())
To reproduce the results in [2] run the following:
th examples/multigpu-nce-rnnlm.lua --startlr 0.7 --saturate 300 --minlr 0.001 --cutoff 10 --progress --uniform 0.1 --seqlen 50 --batchsize 128 --trainsize 400000 --validsize 40000 --hiddensize '{2048,2048,2048,2048}' --dropout 0.2 --k 400 --Z 1 --momentum -1
Notable differences to paper are the following:
- we use a gradient norm clipping [3] (with a
cutoffnorm of 10) to counter exploding and vanishing gradient; - they use an adaptive learning rate schedule (which isn’t specified in the paper). We linearly decay from a learning rate of 0.7 (which they also start from) such that it reaches 0.001 after 300 epochs;
- we use
k=400samples whereas they usek=100. Why? I didn’t see a major drop in speed, so why not? - we use a sequence length of
seqlen=50for Truncated BPTT. They use 100 (again, not in the paper). The average length of sentences in the dataset is 27 so 50 is more than enough.
Like them, we use a dropout=0.2 between LSTM layers.
This is what the resulting model looks like:
nn.Serial @ nn.Sequential {
[input -> (1) -> (2) -> (3) -> output]
(1): nn.ParallelTable {
input
|`-> (1): nn.Sequential {
| [input -> (1) -> (2) -> (3) -> (4) -> (5) -> (6) -> (7) -> (8) -> (9) -> (10) -> (11) -> (12) -> output]
| (1): nn.Convert
| (2): nn.GPU(2) @ nn.Concat {
| input
| |`-> (1): nn.GPU(1) @ nn.LookupTableMaskZero
| |`-> (2): nn.GPU(2) @ nn.LookupTableMaskZero
| ... -> output
| }
| (3): nn.GPU(2) @ nn.Dropout(0.2, busy)
| (4): nn.GPU(1) @ nn.SeqLSTM
| (5): nn.GPU(1) @ nn.Dropout(0.2, busy)
| (6): nn.GPU(1) @ nn.SeqLSTM
| (7): nn.GPU(1) @ nn.Dropout(0.2, busy)
| (8): nn.GPU(2) @ nn.SeqLSTM
| (9): nn.GPU(2) @ nn.Dropout(0.2, busy)
| (10): nn.GPU(2) @ nn.SeqLSTM
| (11): nn.GPU(2) @ nn.Dropout(0.2, busy)
| (12): nn.GPU(3) @ nn.SplitTable
| }
|`-> (2): nn.Identity
... -> output
}
(2): nn.ZipTable
(3): nn.GPU(3) @ nn.Sequencer @ nn.Recursor @ nn.MaskZero @ nn.NCEModule(2048 -> 793471)
}
Results
On the 4-layer LSTM with 2048 hidden units, [1] obtain 43.2 perplexity on the GBW test set. After early-stopping on a sub-set of the validation set (at 100 epochs of training where 1 epoch is 128 sequences x 400k words/sequence), our model was able to reach 40.61 perplexity.
This model was run on 4x12GB NVIDIA Titan X GPUs. Training requires approximately 40GB of memory distributed across the 4 GPU devices, and 2-3 weeks of training. As in the original paper, we do not make use of momentum as it provides little benefit and requires 1/2 more memory.
Training runs at about 3800 words/second.
Learning curves
The following figure outlines the learning curves for the above 4x2048 LSTM model.
The figure plots the NCE training and validation error for the model, which is the error output but the NCEModule.
Test set error isn’t plotted as doing so for any epoch requires about 3 hours because test set inference uses Linear + SoftMax with batchsize=1.
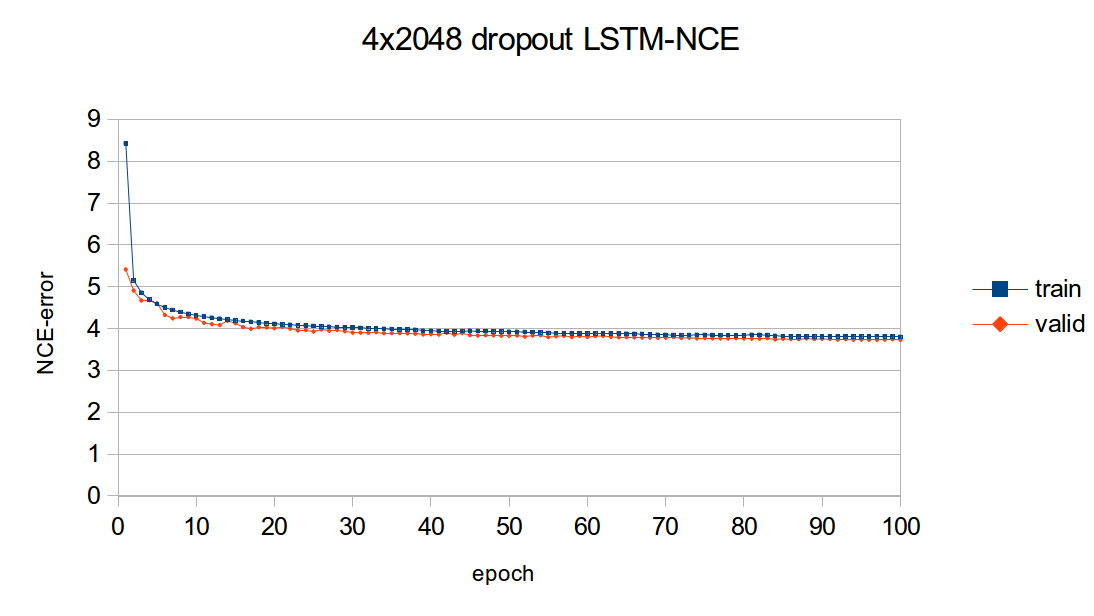
As you can see, most of the learning is done in the first epochs. Nevertheless, the training and validation error are consistently reduced training progresses.
The following figure compares the valiation learning curves (again, NCE error) for a small 2x250 LSTM (no dropout) and big 4x2048 LSTM (with dropout).
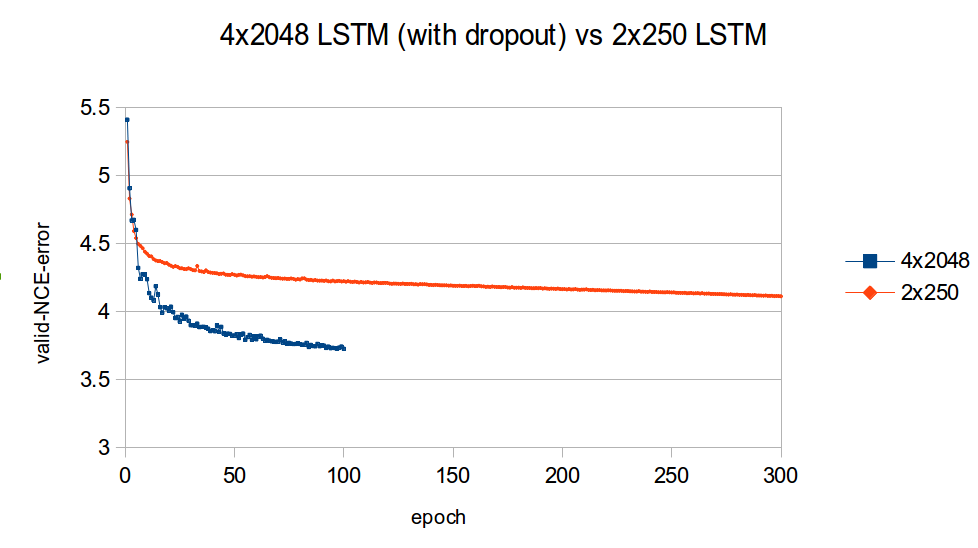
What I find impressive about this figure is how quickly the higher-capacity model bests the lower-capacity model. This clearly demonstrates the importance of capacity when optimizing large-scale language models.
Generating sentences
Here are some sentences sampled independently from the 4-layer LSTM with a temperature or 0.7:
<S> The first , for a lot of reasons , is the " Asian Glory " : an American military outpost in the middle of an Iranian desert . </S>
<S> But the first new stage of the project will be a new <UNK> tunnel linking the new terminal with the new terminal at the airport . </S>
<S> The White House said Bush would also sign a memorandum of understanding with Iraq , which will allow the Americans to take part in the poll . </S>
<S> The folks who have campaigned for his nomination know that he is in a fight for survival . </S>
<S> The three survivors , including a woman whose name was withheld and not authorized to speak , were buried Saturday in a makeshift cemetery in the town and seven people were killed in the town of Eldoret , which lies around a dozen miles ( 40 kilometers ) southwest of Kathmandu . </S>
<S> The art of the garden was created by pouring water over a small brick wall and revealing that an older , more polished design was leading to the creation of a new house in the district . </S>
<S> She added : " The club has not made any concession to the club 's fans and was not notified of the fact they had reached an agreement with the club . </S>
<S> The Times has learnt that the former officer who fired the fatal shots must have known about the fatal carnage . </S>
<S> Obama supporters say they 're worried about the impact of the healthcare and energy policies of Congress . </S>
<S> Not to mention the painful changes to the way that women are treated in the workplace . </S>
<S> The dollar stood at 14.38 yen ( <UNK> ) and <UNK> Swiss francs ( <UNK> ) . </S>
<S> The current , the more intractable <UNK> , the <UNK> and the <UNK> about a lot of priorities . </S>
<S> The job , which could possibly be completed in 2011 , needs to be approved in a new compact between the two companies . </S>
<S> " The most important thing for me is to get back to the top , " he said . </S>
<S> It was a one-year ban and the right to a penalty . </S>
<S> The government of president Michelle Bachelet has promised to maintain a " strong and systematic " military presence in key areas and to tackle any issue of violence , including kidnappings . </S>
<S> The six were scheduled to return to Washington on Wednesday . </S>
<S> " It 's a ... mistake , " he said . </S>
<S> The government 's offensive against the rebels and insurgents has been criticized by the United Nations and UN agencies . </S>
<S> " Our <UNK> model is not much different from many of its competitors , " said Richard Bangs , CEO of the National Center for Science in the Public Interest in Chicago . </S>
<S> He is now a large part of a group of young people who are spending less time studying and work in the city . </S>
<S> He said he was confident that while he and his wife would have been comfortable working with him , he would be able to get them to do so . </S>
<S> The summer 's financial meltdown is the worst in decades . </S>
<S> It was a good night for Stuart Broad , who took the ball to Ravi Bopara at short leg to leave England on 88 for five at lunch . </S>
<S> And even for those who worked for them , almost everything was at risk . </S>
<S> The new strategy is all part of a stepped-up war against Taliban and al-Qaida militants in northwest Pakistan . </S>
<S> The governor 's office says the proposal is based on a vision of an outsider in the town who wants to preserve the state 's image . </S>
<S> " The fact that there is no evidence to support the claim made by the government is entirely convincing and that Dr Mohamed will have to be detained for a further two years , " he said . </S>
<S> The country 's tiny nuclear power plants were the first to use nuclear technology , and the first such reactors in the world . </S>
<S> " What is also important about this is that we can go back to the way we worked and work and fight , " he says . </S>
<S> And while he has been the star of " The Wire " and " The Office , " Mr. Murphy has been a careful , intelligent , engaging competitor for years . </S>
<S> On our return to the water , we found a large abandoned house . </S>
<S> The national average for a gallon of regular gas was $ 5.99 for the week ending Jan . </S>
<S> The vote was a rare early start for the contest , which was held after a partial recount in 26 percent of the vote . </S>
<S> The first one was a show of force by a few , but the second was an attempt to show that the country was serious about peace . </S>
<S> It was a little more than half an hour after the first reports of a shooting . </S>
<S> The central bank is expected to cut interest rates further by purchasing more than $ 100 billion of commercial paper and Treasuries this week . </S>
<S> Easy , it 's said , to have a child with autism . </S>
<S> He said : " I am very disappointed with the outcome because the board has not committed itself . </S>
<S> " There is a great deal of tension between us , " said Mr C. </S>
<S> The odds that the Fed will keep its benchmark interest rate unchanged are at least half as much as they were at the end of 2008 . </S>
<S> For them , investors have come to see that : a ) the government will maintain a stake in banks and ( 2 ) the threat of financial regulation and supervision ; and ( 3 ) it will not be able to raise enough capital from the private sector to support the economy . </S>
<S> The court heard he had been drinking and drank alcohol at the time of the attack . </S>
<S> " The whole thing is quite a bit more intense . </S>
<S> This is a very important project and one that we are working closely with . </S>
<S> " We are confident that in this economy and in the current economy , we will continue to grow , " said John Lipsky , who chaired the IMF 's board of governors for several weeks . </S>
<S> The researchers said they found no differences among how men drank and whether they were obese . </S>
<S> Even though there are many brands that have low voice and no connection to the Internet , the iPhone is a great deal for consumers . </S>
<S> The £ 7m project is a new project for the city of Milton Keynes and aims to launch a new challenge for the British Government . </S>
<S> But he was not without sympathy for his father . </S>
The syntax seems quite reasonable, especially when comparing it to the previous results obtained from the single-GPU 2x250 LSTM. However, in some cases, the semantics, i.e. the meaning of the words, is not so good. For example, the sentence
<S> Easy , it 's said , to have a child with autism . </S>
would make more sense, to me at least, by replacing Easy with Not easy.
On the other hand, sentences like this one demonstrate good semantics:
<S> The government of president Michelle Bachelet has promised to maintain a " strong and systematic " military presence in key areas and to tackle any issue of violence , including kidnappings . </S>`.
Michelle Bachelet was actually a president of Chile. In her earlier life, she was also kidnapped by military men, so it kind of makes sense that she would be strong on the issue of kidnappings.
Here is an example of some weird semantics :
<S> Even though there are many brands that have low voice and no connection to the Internet , the iPhone is a great deal for consumers . </S>
The first part about load voice doesn’t mean anything to me.
And I fail to see how there being many brands that have no connection to the Internet relates to the iPhone is a great deal for consumers.
But of course, all these sentences are generated independently, so the LM needs to learn to generate a meaning on the fly.
This is hard as there is no context to the sentence being generated.
In any case, I am quite happy with the results as they are definitely some of the most natural-looking synthetic sentences I have seen so far.
Future work
I am currently working on a language modeling dataset based on one month of reddit.com data.
Each sequence is basically a reddit submission consisting of a TITLE, SELFTEXT (or URL), SCORE, AUTHOR and a thread of COMMENTS.
These sequences are much longer (average of 205 tokens) than the sentences that make up the GBW dataset (average of 26 tokens).
Training is still underway, but to pique your interest, this is an example of generated data (indentation and line breaks added for clarity):
<SUBMISSION>
<AUTHOR> http://www.reddit.com/u/[deleted] </AUTHOR>
<SCORE> 0 </SCORE>
<TITLE>
[ WP ] You take a picture of a big bang .
You discover an alien that lives in the center of the planet in an unknown way .
You can say " what the fuck is that ? "
</TITLE>
<COMMENTS>
<CoMMeNT>
<ScoRE> 2 </ScoRE>
<AuTHoR> http://www.reddit.com/u/Nev2k </AuTHoR>
<BodY>
I have a question .
When i was younger , my parents had a house that had a living room in it .
One that was only a small portion of an entire level .
This was a month before i got my money .
If i was living in a house with a " legacy " i would make some mistakes .
When i was a child , i did n't know how to do shit about the house .
My parents got me into my own house and i never found a place to live .
So i decide to go to college .
I was so freaked out , i didnt have the drive to see them .
I never had a job , i was n't going anywhere .
I was so happy .
I knew i was going to be there .
I gave myself a job and my parents came .
That 's when i realized that i was in the wrong .
So i started to go .
I couldnt decide how long i wanted to live in this country .
I was so excited about the future .
I had a job .
I saved my money .
I did n't have a job .
I went to a highschool in a small town .
I had a job .
A job .
I did n't know what to do .
I was terrified of losing my job .
So i borrowed my $ 1000 in an hour .
I could n't afford to pay my rent .
I was so low on money .
I had my parents and i got into a free college .
I got in touch with my parents .
All of my friends were dead .
I was still with my family for a week .
I became a good parent .
I was a good choice .
When i got on my HSS i was going to go to my parents ' house .
I started to judge my parents .
I had a minor problem .
My parents .
I was so fucking bad .
My sister had a voice that was very loud .
I 'm sure my cousins were in a place where i could just hear my voice .
I felt like i was supposed to be angry .
I was so angry .
To cope with this .
My dad and i were both on break and i felt so alone .
I got unconscious and my mum left .
When I got to college , i was back in school .
I was a good kid .
I was happy .
And I told myself I was ready .
I told my parents .
They always talked about how they were going to be a good mom , and that I was going to be ready for that .
They always wanted to help me .
I did n't know what to do .
I had to .
I tried to go back to my dad , because I knew a lot about my mom .
I loved her .
I cared about her .
We cared for our family .
The time together was my only relationship .
I loved my heart .
And I hated my mother .
I chose it .
I cried . I cried . I cried . I cried . I cried . I cried . I cried .
The tears were gone .
I cried . I cried . I cried . I cried . I cried . I cried . I cried . I cried . I cried . I cried .
I do n't know how to do it .
I do n't know how to deal with it .
I ca n't feel my emotions .
I ca n't get out of bed .
I ca n't sleep .
I ca n't tell my friends .
I just need to leave .
I want to leave .
I hate myself .
I hate feeling like I 'm being selfish .
I feel like I 'm not good enough anymore .
I need to find a new job .
I hate that I have to get my shit together .
I love my job .
I 'm having a hard time .
Why do I need to get a job ?
I have no job .
I have n't been feeling good lately .
I feel like I 'm going to be so much worse in the long run .
I feel so alone .
I ca n't believe I 'm so sad about going through my entire life .
</BodY>
<AuTHoR> http://www.reddit.com/u/Scarbarella </AuTHoR>
</CoMMeNT>
</COMMENTS>
<SUBREDDIT> http://www.reddit.com/r/offmychest </SUBREDDIT>
<SELFTEXT>
I do n't know what to do anymore .
I feel like I 'm going to die and I 'm going to be sick because I have no more friends .
I do n't know what to do about my depression and I do n't know where to go from here .
I do n't know how I do because I know I 'm scared of being alone .
Any advice would be appreciated .
Love .
</SELFTEXT>
</SUBMISSION>
This particular sample is a little depressing, but that might just be the nature of the offmychest subreddit.
Conditioned on the opening <SUBMISSION> token, this generated sequence, although imperfect, is incredibly human.
Reading through the comment, I feel like I am reading a story written by an actual (somewhat schizophrenic) person.
The ability to similuate human creativity is one of the reasons I am so interested in using reddit data for language modeling.
A less depressing sample is the following, which concerns the Destiny video game:
<SUBMISSION>
<SUBREDDIT> http://www.reddit.com/r/DestinyTheGame </SUBREDDIT>
<TITLE>
Does anyone have a link to the Destiny Grimoire that I can use to get my Xbox 360 to play ?
</TITLE>
<COMMENTS>
<CoMMeNT>
<AuTHoR> http://www.reddit.com/u/CursedSun </AuTHoR>
<BodY>
I 'd love to have a weekly reset .
</BodY>
<ScoRE> 1 </ScoRE>
</CoMMeNT>
</COMMENTS>
<SCORE> 0 </SCORE>
<SELFTEXT>
I have a few friends who are willing to help me out .
If I get to the point where I 'm not going to have to go through all the weekly raids , I 'll have to " complete " the raid .
I 'm doing the Weekly strike and then doing the Weekly ( and hopefully also the Weekly ) on Monday .
I 'm not planning to get the chest , but I am getting my first exotic that I just got done from my first Crota raid .
I 'm not sure how well it would work for the Nightfall and Weekly , but I do n't want to loose my progress .
I 'd love to get some other people to help me , and I 'm open to all suggestions .
I have a lot of experience with this stuff , so I figured it 's a good idea to know if I 'm getting the right answer .
I 'm truly sorry for the inconvenience .
</SELFTEXT>
<AUTHOR> <OOV> </AUTHOR>
</SUBMISSION>
For those not familiar with this game, terms like Grimoire, weekly reset, raids, Nightfall stike, exotics and Crota raid may seem odd. But these are all part of the game vocabulary.
The particular model (a 4x1572 LSTM with dropout) only backpropagates through 50 time-steps.
What I would like to see is for the COMMENTS to actually answer the question posed by the TITLE and SELFTEXT.
This is a very difficult semantic problem which I hope the Reddit dataset will help solve.
More to follow in my next Torch blog post.
References
- A Mnih, YW Teh, A fast and simple algorithm for training neural probabilistic language models
- B Zoph, A Vaswani, J May, K Knight, Simple, Fast Noise-Contrastive Estimation for Large RNN Vocabularies
- R Pascanu, T Mikolov, Y Bengio, On the difficulty of training Recurrent Neural Networks
- S Hochreiter, J Schmidhuber, Long Short Term Memory
- A Graves, A Mohamed, G Hinton, Speech Recognition with Deep Recurrent Neural Networks
- K Greff, RK Srivastava, J Koutník, LSTM: A Search Space Odyssey
- C Chelba, T Mikolov, M Schuster, Q Ge, T Brants, P Koehn, T Robinson, One billion word benchmark for measuring progress in statistical language modeling
- A Graves, Generating Sequences With Recurrent Neural Networks, table 1